
Narzędzia monitorowania i analizy działania procesów dostępne w platformie docuRob®WorkFlow są podstawowym środowiskiem administratorów aplikacji oraz kierownictwa merytoryczne działalności organizacji. W pełni zdefiniowane procesy są uruchamiane w środowisku docelowym wspierając organizację w osiąganiu założonych celów. Wykonywane procesy są odzwierciedlane poprzez pełną historię ich wykonania. Dane te umożliwiają zarówno monitorowanie procesów jak i wykonywanie złożonych analiz w celu ich optymalizacji.
Monitorowanie działania procesów jest zasadniczo celem krótkoterminowym ukierunkowanym na identyfikację sytuacji wyjątkowych i szybkie minimalizowanie ich skutków w wykonywanych procesach.
Analiza wykonania jest związana z długoterminowym celem ukierunkowanym na ciągłą optymalizację procesów identyfikując nieefektywne elementy i starając się wypracować nową, lepszą wersję definicji danego procesu.
Analiza obciążenia pracą jest skoncentrowana na planowaniu i organizacji zasobów ludzkich których uczestnictwo w procesach biznesowych jest ważnym elementem modelowania procesów oraz ich wdrażania i eksploatacji. Ważną cechą tego obszaru projektowego jest analiza z punktu widzenia optymalizacji parametrów wydajnościowych procesów biznesowych podejmowana zarówno na etapie projektowania jak i konserwacji aplikacji.
System udostępnia otwarty i elastyczny mechanizm dostępu do historii wykonania poprzez repozytorium danych procesów. Repozytorium to jest dostępne w postaci obiektów (tabel i widoków) relacyjnej bazy danych. Mechanizm oparty o repozytorium umożliwia podłączanie do systemu dowolnych zewnętrznych narzędzi analitycznych i raportujących operujących na bazie danych.
Monitorowanie działania procesów
Monitorowanie procesów jako działanie zorientowane na wykrywanie i usuwanie przyczyn sytuacji wyjątkowych dotyczy zazwyczaj jednej instancji procesu i ewentualnie instancji powiązanych z nią procesów. Przedmiotem działań diagnostycznych są przede wszystkim trzy elementy konfiguracji platformy docuRob®WorkFlow a mianowicie: (1) graf historii wykonania procesu i jego forma tabelaryczna, (2) wartości zmiennych globalnych oraz parametrów procesu zawartych w jego kontenerze oraz (3) graficzny model procesu i zawarte w nim skrypty BPQL sterujące wykonaniem czynności i przepływów procesu.
Graf historii wykonania instancji procesu jest zgodny z notacją graficzną BPMN 2.02 i dodatkowo zawiera dane związane z przebiegiem przetwarzania procesu takie jak czasowe atrybuty zadań, warunki przepływów oraz wystąpienia zdarzeń. Dodatkowo Ewaluacja wyrażeń BPQL pozwala na weryfikację skryptów i warunków przepływów oraz zdarzeń sterujących wyborem ścieżek przebiegu procesu.
Poprawne działanie procesów wymaga spójności ich implementacji z logiką wspieranych przez nie procedur biznesowych. Weryfikacja tego wymagania jest możliwa wyłącznie przy współpracy pomiędzy projektantami procesu a osobami odpowiedzialnymi za zarządzanie organizacją. Wobec bogatej reprezentacji semantyki procesów dostępnej w systemie konieczna jest ocena uwzględniająca wielowymiarowość informacji projektowej reprezentującej różne fazy modelowania.
Przedstawiamy poniżej przykład analizy procesu pracy grupowej opartej o przedstawione na Rysunkach 1 do Rysunek 5 aspekty jego semantyki reprezentujące istotne cechy jego modelu i rzeczywistych przebiegów.
Obiekt przetwarzany w ramach poszczególnych zadań procesu to tekst publikacji naukowej a zarządzana przez proces praca grupowa jest typowym przykładem właściwie zorganizowanej procedury wydawniczej. Ponieważ proces korzysta ze wspólnego repozytorium obiektów, w tym wypadku tekstów publikacji naukowych, nie ma potrzeby reprezentowania przepływu danych w ramach procesu.
Procedura wydawnicza przewiduje, że opracowanie przedstawione do recenzji zostanie poddane automatycznej weryfikacji kompletności i relewancji przywołanej bibliografii oraz językowej poprawności publikacji.
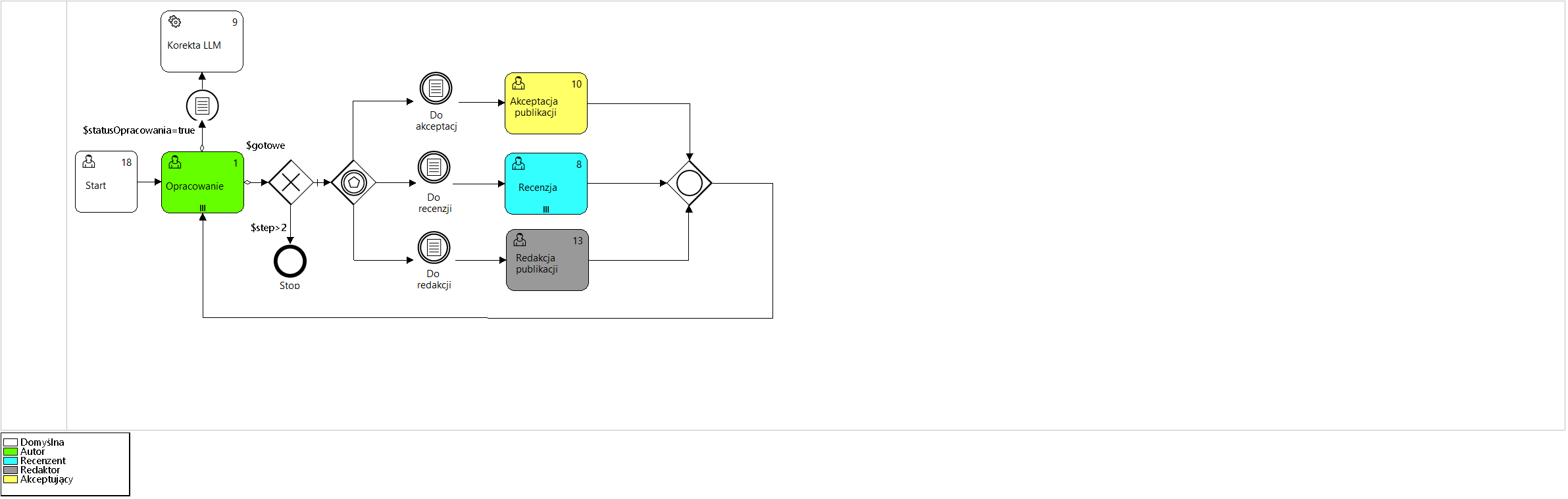
Rysunek 2. Model procesu „Praca grupowa”
Analizując przedstawiony model procesu (Rysunek 2) widzimy, że po zakończeniu zadania „Opracowanie” (Przepływ wychodzący OR) wobec wartości „true” logicznych zmiennych globalnych $statusOpracowania i $gotowe oraz zachodzącego warunku zdefiniowanego predykatem „$statusLLM=true AND $doneLLM=false”., zostanie wykonana automatyczna analiza tekstu opracowania przez system LLM (ang. large language model). Bieżące wartości zmiennych logicznych są dostępne w kontenerze procesu (Rysunek 5).
Oznaczenie zadania nr 1 („Opracowanie”) markerem ||| oznacza, że więcej niż jeden autor może równolegle pracować nad publikacją w trakcie czynności wielokrotnej. Zadanie będzie zakończone po wykonaniu pracy przez wszystkich jego uczestników.
Rysunek 3 pokazuję kolorystyczną legendę symboli grafu historii wykonania dostępny w prawym górnym rogu okna. Wypustki umieszczona na dolnej krawędzi symboli grafu pokazują kolejny numer wykonania czynności i przyjmują kolorystyczną reprezentację stanu czynności.
Rysunek 3. Legenda kolorystycznej reprezentacji stanu procesu
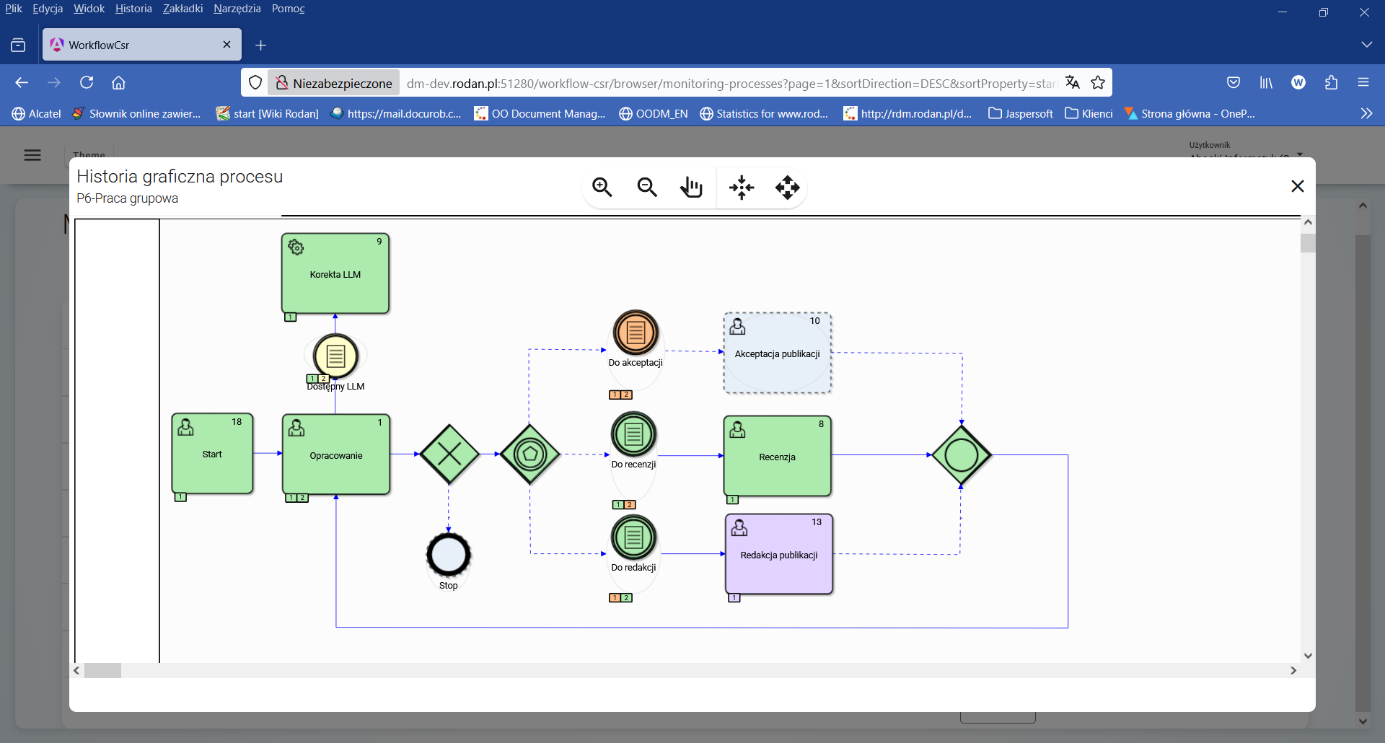
Rysunek 4. Graf historii wykonania instancji procesu „Praca grupowa”
Analizując stan wykonania instancji procesu „P6-Praca grupowa”, który pokazuje Rysunek 4, widzimy, że zostały już wykonana 2 iteracje zadania „Opracowanie” przy czym druga iteracja została wykonana po opracowaniu Recenzji. Przy odpowiednim ustawieniu zmiennej logicznej $doneLLM automatyczna analiza tekstu publikacji jest wykonywana tylko raz przed zadaniem „Recenzja”.
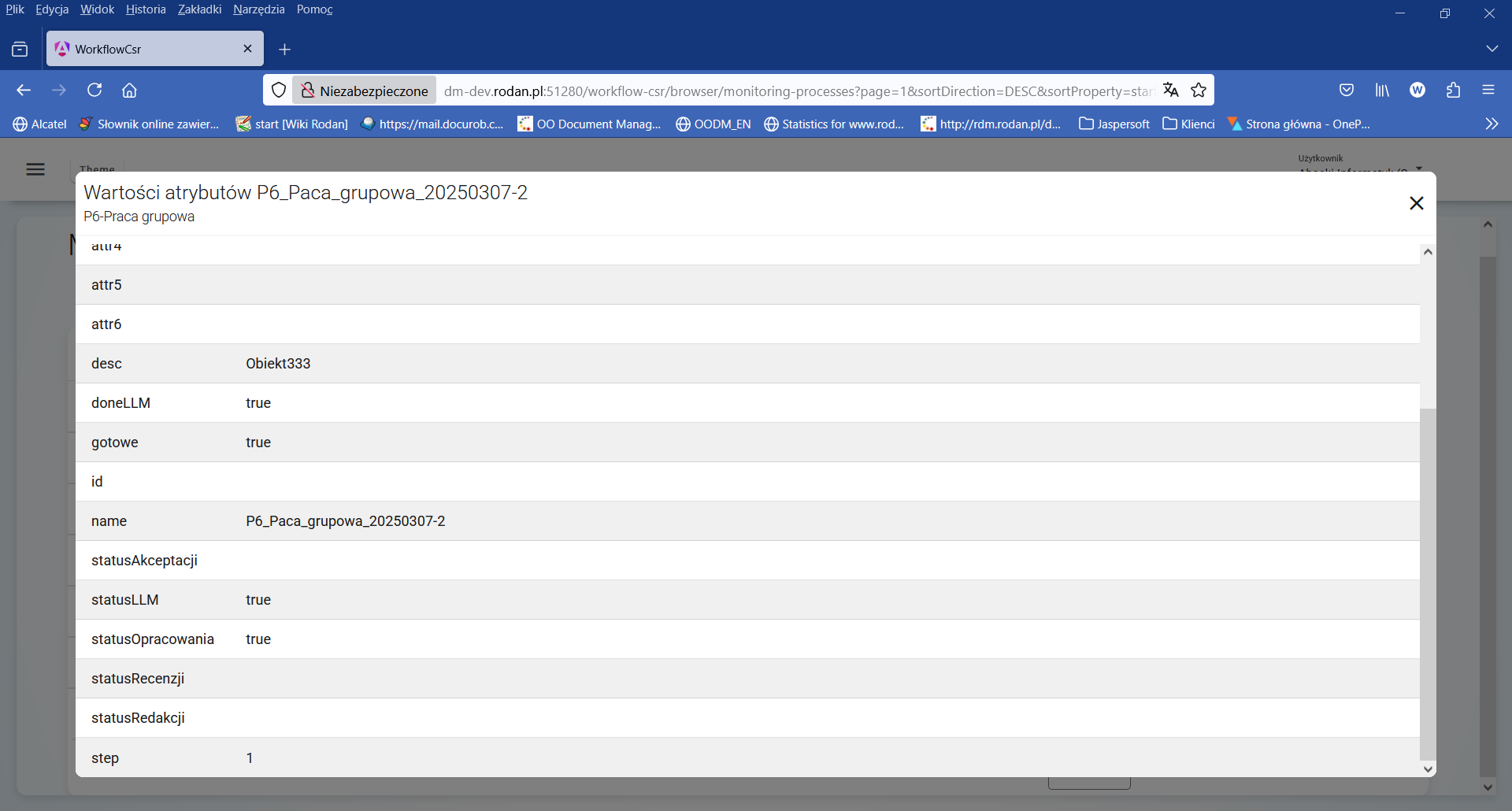
Rysunek 5. Wartości atrybutów instancji procesu „Praca grupowa”
W tym momencie analizy stanu instancji procesu, po wykonaniu pierwszego kroku iteracji (wartość zmiennej $step=1), proces oczekuje na podjęcie zadania „Redakcja publikacji” przez osobę pełniącą rolę „Redaktor”.
Analiza wykonania procesów
Repozytorium danych procesów
Historia wykonywanych procesów dostępna jest w postaci perspektyw (ang. view) w bazie danych systemu. Udostępnienie dostępu do nich upoważnionym użytkownikom umożliwia wyszukiwania złożonych informacji o procesach zapewniając jednocześnie, że dane te będą wykorzystywane jedynie do odczytu (brak zagrożenia związanego z ewentualną modyfikacją danych w Repozytorium).
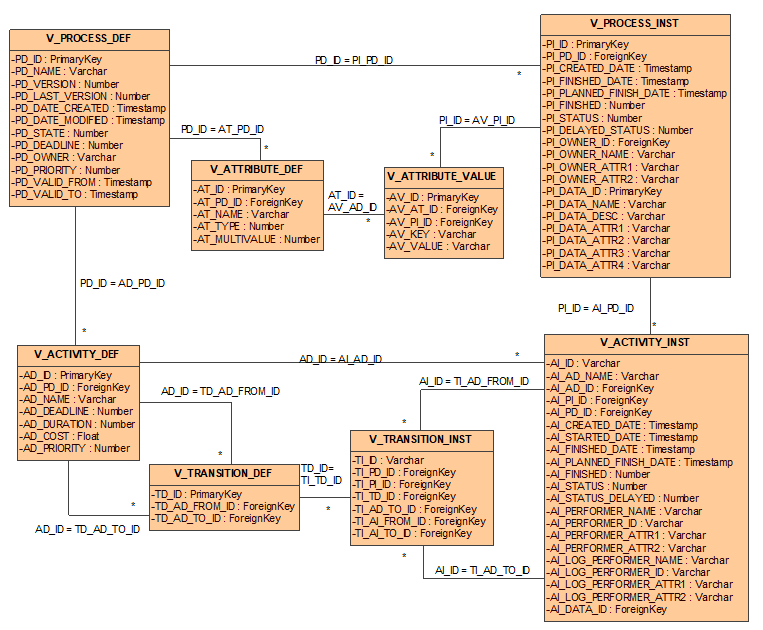
Rysunek 6. Perspektywy schematu bazy danych procesów
Udostępniane dane dotyczą definicji procesów oraz instancji procesów. Dane te są zgodne z metamodelem procesu odzwierciedlając jego strukturę fizyczną w relacyjnej bazie danych.
Definicje procesów dostępne są poprzez perspektywę V_PROCESS_DEF. Znaczenie poszczególnych pól tej perspektywy pokazuje Tabela 1.
| Nazwa pola | Znaczenie |
|---|---|
| PD_ID | Unikalny na poziomie bazy identyfikator wersji definicji procesu. |
| PD_NAME | Nazwa procesu. Nazwa jest unikalna na poziomie definicji procesu (wszystkich jego wersji). |
| PD_VERSION | Numer wersji danej definicji procesu. Wersje są numerowane rosnąco od 1. |
| PD_LAST_VERSION | Określa, czy dana definicja jest ostatnią wersją (wartość 1) procesu. Jeżeli nie, to pole to ma wartość 0. |
| PD_DATE_CREATED | Data i czas utworzenia definicji procesu w systemie. |
| PD_DATE_MODIFIED | Data i czas ostatniej modyfikacji tej wersji definicji procesu. |
| PD_STATE | Stan definicji procesu. Wartość 0 oznaczą, że definiowanie lub modyfikowanie procesu. Wartość 1 oznacza, że definicja kompletna i została udostępniona. |
| PD_DEADLINE | Interwał czasu przez jaki maksymalnie może wykonywać się proces. Interwał ten jest podawany w milisekundach. |
| PD_PRIORITY | Priorytet definicji procesu. Im wyższa wartość, tym wyższy priorytet. |
| PD_OWNER | Identyfikator właściciela procesu. |
| PD_VALID_FROM | Określa od kiedy dana definicja jest ważna. |
| PD_VALID_TO | Określa do kiedy dana definicja jest ważna. |
Tabela 1. Atrybuty perspektywy V_PROCESSDEF
Atrybuty (zmienne) procesu są definiowane poprzez perspektywę V_ATTRIBUTE_DEF. Znaczenie poszczególnych pól tej perspektywy zawiera Tabela 2.
| Nazwa pola | Znaczenie |
|---|---|
| AT_ID | Unikalny na poziomie bazy identyfikator atrybutu procesu.. |
| AT_PD_ID | Identyfikator definicji procesu, do której należy dany atrybut. |
| AT_NAME | Nazwa atrybutu. |
| AT_TYPE | Nazwa typu atrybutu zgodnie ze standardowymi typami zdefiniowanymi w systemie docuRob®WorkFlow. |
| AT_MULTIVALUE | Flaga wskazująca, czy atrybut jest wielowartościowy (wartość 1), czy jest wartością pojedynczą (wartość 0). |
Tabela 2. Atrybuty perspektywy V_ATTRIBUTE_DEF
Każda z czynności w procesie reprezentowana jest poprzez perspektywę V_ACTIVITY_DEF (Tabela 3).
| Nazwa pola | Znaczenie |
|---|---|
| AD_ID | Unikalny na poziomie bazy identyfikator definicji czynności.. |
| AD_PD_ID | Identyfikator definicji procesu, do której należy dana czynność. |
| AD_NAME | Nazwa czynności. |
| AD_DEADLINE | Interwał czasu jaki maksymalnie może upłynąć od rozpoczęcia wykonywania instancji procesu, aby czynność nie była opóźniona. Interwał ten jest podawany w milisekundach. |
| AD_DURATION | Interwał czasu reprezentujący maksymalny czas wykonania danej czynności. Interwał ten jest podawany w milisekundach. |
| AD_PRIORITY | Priorytet definicji procesu. Im wyższa liczba, tym wyższy priorytet. |
| AD_COST | Estymowany koszt wykonania czynności. |
Tabela 3. Atrybuty perspektywy V_ACTIVITY_DEF
Przejścia pomiędzy czynnościami są definiowane w tabeli V_TRANSITION_DEF. Znaczenie poszczególnych pól tej perspektywy pokazuje Tabela 4.
| Nazwa pola | Znaczenie |
|---|---|
| TD_ID | Unikalny na poziomie bazy identyfikator tranzycji czynności. |
| TD_AD_FROM_ID | Identyfikator definicji czynności, od której jest wykonywane przejście. |
| TD_AD_TO_ID | Identyfikator definicji czynności, do której jest wykonywane przejście. |
Tabela 4. Atrybuty perspektywy V_TRANSITION_DEF
Instancje wykonywanych procesów są reprezentowane poprzez perspektywę V_PROCESS_INST (Tabela 5).
| Nazwa pola | Znaczenie | |
|---|---|---|
| PI_ID | Unikalny na poziomie bazy identyfikator wykonywanego procesu (instancji procesu).. | |
| PI_PD_ID | Identyfikator definicji procesu, zgodnie z którą został uruchomiony proces. | |
| PI_CREATED_DATE | Data uruchomienia instancji procesu. | |
| PI_FINISHED_DATE | Data zakończenia instancji procesu. | |
| PI_PLANNED_FINISH_DATE | Planowana data zakończenia procesu wyliczona według zdefiniowanych ograniczeń czasowych. | |
| PI_FINISHED | Flaga określająca, czy wykonywanie procesu zakończyło się. Wartość 0 oznacza, że proces nie zakończył się. Wartość 1 oznacza, że proces został zakończony. | |
| PI_STATUS | Status realizacji procesu. Dopuszczalne są następujące wartości: 0 – instancja procesu jest uruchomiona, 1 – instancja procesu została zakończona, 2 – instancja procesu została przerwana. | |
| PI_DELAYED_STATUS | Status opóźnienia procesu. Dopuszczalne są następujące wartości: 0 – instancja procesu nie jest opóźniona, 1 – instancja procesu jest opóźniona. | |
| PI_OWNER_ID | Identyfikator pracownika organizacji będącego właścicielem instancji procesu. | |
| PI_OWNER_NAME | Nazwa (najczęściej imię, nazwisko i skrót komórki organizacyjnej) właściciela procesu. | |
| PI_OWNER_ATTR1 | Dodatkowy atrybut nr 1 identyfikujący właściciela procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator jednostki organizacyjnej, do której należy pracownik | |
| PI_OWNER_ATTR2 | Dodatkowy atrybut nr 2 identyfikujący właściciela procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator komórki organizacyjnej, do której należy pracownik | |
| PI_DATA_ID | Atrybuty związane ze specyficznymi danymi aplikacji, przechowywanymi w systemie docuRob®WorkFlow ze względów wydajnościowych. Dane te są najczęściej wykorzystywane do reprezentacji: danych wyświetlanych i sortowanych na liście zadań, identyfikatorów do danych wykorzystywanych w regułach procesu. | |
| PI_DATA_NAME | ||
| PI_DATA_DESC | ||
| PI_DATA_ATTR1 | ||
| PI_DATA_ATTR2 | ||
| PI_DATA_ATTR3 | ||
| PI_DATA_ATTR4 |
Tabela 5. Atrybuty perspektywy V_PROCESS_INST
Atrybuty (zmienne) wykonywanego procesu są reprezentowane poprzez perspektywę V_ATTRIBUTE_VALUE. Znaczenie poszczególnych pól tej perspektywy pokazuje Tabela 6.
| Nazwa pola | Znaczenie |
|---|---|
| AV_ID | Unikalny na poziomie bazy identyfikator atrybutu wykonywanego procesu.. |
| AV_AT_ID | Identyfikator definicji atrybutu. |
| AV_PI_ID | Identyfikator instancji procesu, do której należy dany atrybut. |
| AV_KEY | Wartość klucza atrybutu. |
| AV_VALUE | Wartość atrybutu. |
Tabela 6. Atrybuty perspektywy V_ATTRIBUTE_VALUE
Czynności wykonywane w ramach procesów są reprezentowane poprzez perspektywę V_ACTIVITY_INST. (Tabela 7).
| Nazwa pola | Znaczenie |
|---|---|
| AI_ID | Unikalny na poziomie bazy identyfikator zdania (instancji czynności). |
| AI_AD_NAME | Nazwa czynności określonej w jej definicji. |
| AI_AD_ID | Identyfikator definicji czynności. |
| AI_PI_ID | Identyfikator instancji procesu, w ramach której uruchamiana jest instancja czynności. |
| AI_PD_ID | Identyfikator definicji procesu, w którym została zdefiniowana dana czynności. |
| AI_CREATED_DATE | Data utworzenia instancji czynności. |
| AI_STARTED_DATE | Data rozpoczęcia wykonywania czynności przez wykonawcę. Jeżeli czynność nie została rozpoczęta, to wartość NULL. |
| AI_PLANNED_FINISH_DATE | Planowana data zakończenia czynności obliczona na podstawie ograniczeń czasowych zdefiniowanych w procesie. |
| AI_FINISHED_DATE | Data zakończenia wykonywania czynności. Jeżeli czynność nie została zakończona, to wartość NULL. |
| AI_FINISHED | Flaga określająca, czy wykonywanie zadania zakończyło się. Wartość 0 oznacza, że proces nie zakończył się. Wartość 1 oznacza, że proces został zakończony. |
| AI_STATUS | Status realizacji zadania. Dopuszczalne są następujące wartości: 0 – zadanie zostało rozpoczęte, 1 – zadanie zostało zakończone, 2 – zadanie zostało przerwane, 3 -zadanie zostało utworzone, ale nie rozpoczęte. |
| AI_DELAYED_STATUS | Status opóźnienia procesu. Dopuszczalne są następujące wartości: 0 – instancja procesu nie jest opóźniona, 1 – instancja procesu jest opóźniona. |
| AI_PERFORMER_ID | Identyfikator pracownika organizacji będącego rzeczywistym wykonawcą zadania. W przypadku wykonywania zadania w zastępstwie innej osoby tutaj wpisywane są dane zastępującego. |
| AI_PERFORMER_NAME | Nazwa (najczęściej imię, nazwisko i skrót komórki organizacyjnej) rzeczywistego wykonawcy procesu. |
| AI_PERFORMER_ATTR1 | Dodatkowy atrybut nr 1 identyfikujący rzeczywistego wykonawcę procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator jednostki organizacyjnej, do której należy pracownik |
| AI_PERFORMER_ATTR2 | Dodatkowy atrybut nr 2 identyfikujący rzeczywistego wykonawcę procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator komórki organizacyjnej, do której należy pracownik |
| AI_LOG_PERFORMER_ID | Identyfikator pracownika organizacji będącego logicznym wykonawcą zadania. W przypadku wykonywania zadania w zastępstwie innej osoby tutaj wpisywane są dane zastępowanego. |
| AI_LOG_PERFORMER_NAME | Nazwa (najczęściej imię, nazwisko i skrót komórki organizacyjnej) logicznego wykonawcy procesu. |
| AI_LOG_PERFORMER_ATTR1 | Dodatkowy atrybut nr 1 identyfikujący logicznego wykonawcę procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator jednostki organizacyjnej, do której należy pracownik |
| AI_LOG_PERFORMER_ATTR2 | Dodatkowy atrybut nr 2 identyfikujący logicznego wykonawcę procesu jako pracownika organizacji. Wartość tego atrybutu zależy od aplikacji wykorzystujących system docuRob®WorkFlow. Najczęściej atrybut ten reprezentuje identyfikator komórki organizacyjnej, do której należy pracownik |
| Atrybuty związane ze specyficznymi danymi aplikacji, przechowywanymi w systemie docuRob®WorkFlow ze względów wydajnościowych. Dane te są najczęściej wykorzystywane do reprezentacji: danych wyświetlanych i sortowanych na liście zadań, identyfikatorów do danych wykorzystywanych w regułach procesu. | |
| AI_DATA_ID | Identyfikator przetwarzanych danych. Tożsamy z PI_DATA_ID. |
Tabela 7. Atrybuty perspektywy V_ACTIVITY_INST
Przepływ sterowania wykonywanych procesów jest reprezentowany poprzez perspektywę V_TRANSITION_INST (Tabela 8).
| Nazwa pola | Znaczenie |
|---|---|
| TI_ID | Unikalny na poziomie bazy identyfikator instancji przejścia. |
| TI_PD_ID | Identyfikator definicji procesu, do której należy dana instancja przejścia. |
| TI_PI_ID | Identyfikator instancji procesu, do której należy dana instancja przejścia. |
| TI_TD_ID | Identyfikator definicji przejścia, którą reprezentuje dana instancja. |
| TI_AD_FROM_ID | Identyfikator definicji czynności, od której prowadzi dane przejście. |
| TI_AD_TO_ID | Identyfikator definicji czynności, do której prowadzi dane przejście. |
| TI_AI_FROM_ID | Identyfikator instancji czynności, od której prowadzi dane przejście. |
| TI_AI_TO_ID | Identyfikator instancji czynności, do której prowadzi dane przejście. |
Tabela 8. Atrybuty perspektywy V_TRANSITION_INST
Przykłady zapytań SQL
Na podstawie perspektyw schematu bazy danych opisanych w poprzedniej sekcji możliwe jest tworzenie dowolnych zapytań dotyczących definicji lub wykonywania procesów. Tworzone zapytania muszą być zgodne ze składnią języka SQL określoną w standardzie SQL'89. Dopuszcza się też pewne specyficzne konstrukcje zależne od typu serwera bazy danych. Użycie ich może przyspieszyć działanie zapytania lub uprościć jego definicję, ale trudniej będzie je uruchomić na innych typach serwerów bazy danych.
UWAGA. Przykłady opisane poniżej zostały przygotowane dla serwera PostgreSQL. W większości przygotowane zapytania są uniwersalne jednak w przypadku operacji na datach oraz jawnej konwersji danych konieczne było wykorzystanie specyficznych, wbudowanych funkcji serwera PostgreSQL. Funkcje te są dostępne także w innych serwerach relacyjnej bazy ale mogą różnić się nazwą i/lub składnią. Problem, który może napotkać osoba uruchamiająca poniższe przykłady na nietypowych serwerach bazy danych to wykorzystanie funkcji w operacjach agregacji danych. Obecnie, większość znanych serwerów wspiera taką możliwość, ale zawsze należy to zweryfikować na podstawie dokumentacji danego serwera.
Monitorowanie procesów
Przy monitorowaniu procesów najczęściej interesuje nas szybka identyfikacja zaistniałych anomalii w wykonywanych procesach. W tym celu weryfikowane jest dotrzymywanie zadanego poziomu jakości wykonania procesu. Poziom ten może być wyrażony przy pomocy standardowych parametrów jakościowych takich jak czas, czy koszt lub może być określony przy pomocy definiowalnych wskaźników procesu zapisywanych w kontenerze procesu (np. poziom satysfakcji klienta).
Przykład nr 1
Cel: Wyznaczenie maksymalnego, średniego i minimalnego opóźnienia wykonywanych czynności.
Realizacja: Wykonanie tego celu oprzemy o następujące zapytanie:
SELECT
MIN(CURRENT_DATE - AI_PLANNED_FINISH_DATE),
AVG(CURRENT_DATE - AI_PLANNED_FINISH_DATE),
MAX(CURRENT_DATE - AI_PLANNED_FINISH_DATE)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = '0' AND -- zadania wykonywane
Now() > AI_PLANNED_FINISH_DATE -- i opóźnione
Zapytanie to odczytuje instancje czynności udostępnione poprzez widok V_ACTIVITY_INST, które są niezakończone i planowany czas realizacji już minął Do wyznaczenia wartości minimalnej, średniej oraz maksymalnego opóźnienia wykorzystano standardowe funkcje agregujące.
UWAGA. Przy odniesieniu do aktualnej daty wykorzystana została wbudowana funkcja CURRENT_DATE dostarczana w serwerze PostgreSQL. Na innych serwerach relacyjnej bazy danych funkcja ta może nazywać się inaczej. Składnia zastosowanego rzutowania jest specyficzna dla serwera PostgreSQL. W innych typach serwerów baz danych składnia jest odmienna.
Przykład nr 2
Cel: Odczyt średniej liczby wykonanych zwrotów w trakcie wykonywania procesu.
Realizacja: W celu wykonania tego zadania przyjmiemy, że liczba zwrotów jest atrybutem (zmienną) kontenera procesu. W momencie kiedy nastąpi zwrot w procesie, zmienna ta jest inkrementowana. Zmienna ta ma nazwę nawrotyIlosc.
Nasze obliczenia będziemy wykonywali dla procesów zakończonych w standardowy sposób ( tzn. nie poprzez przerwanie procesu).
SELECT
PD_NAME,
PD_VERSION,
avg(AV_VALUE::Integer) -- jawna konwersja pola tekstowego na liczbę
FROM
V_ATTRIBUTE_VALUE, V_ATTRIBUTE_DEF, V_PROCESS_DEF, V_PROCESS_INST
WHERE
AT_NAME = 'nawrotyIlosc' AND
PD_ID = AT_PD_ID AND
AV_AT_ID = AT_ID AND
PI_ID = AV_PI_ID AND
PI_FINISHED = 1 AND – tylko zakończone procesy
PI_STATUS = 1 – tylko instancje zakończone poprawnie
GROUP BY
PD_NAME,
PD_VERSION
Ponieważ wszystkie atrybuty (zmienne) procesu są przechowywane w postaci tekstowej, aby zliczyć liczba nawrotów, należy najpierw rzutować wartość atrybutu na liczbę całkowitą Wyniki są grupowane po definicjach procesów – po nazwie definicji oraz wersji. W celu wybrania tylko instancji zakończonych procesów dodane zostały warunki na instancje zakończone i zakończone poprawnie. Warunek „PI_STATUS = 1” jest nadmiarowy, ale jego zastosowanie wymusi wykorzystanie indeksu i znaczące przyspieszenie wyszukiwania danych.
UWAGA. Składnia zastosowanego rzutowania jest specyficzna dla serwera PostgreSQL. W innych typach serwerów baz danych składnia jest odmienna.
Przykład nr 3
Cel: Przygotowanie wskaźnika umożliwiającego szybką reakcję w momencie, gdy liczba procesów aktualnie wykonywanych i opóźnionych więcej niż o 10 dni przekroczy 8% wszystkich wykonywanych procesów
Realizacja: Zadanie to wykonamy w oparciu o dwa zapytania do Repozytorium procesów. Pierwsze zapytanie zliczy nam liczbę wykonywanych procesów, które są opóźnione więcej niż 10 dni.
SELECT
COUNT(*)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = 0 AND
AI_PLANNED_FINISH_DATE < CURRENT_DATE - 10
Drugie zapytanie zliczy nam liczba wszystkich wykonywanych procesów.
SELECT
COUNT(*)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = 0
Stosunek procesów opóźnionych w stosunku do wszystkich uruchomionych procesów wyznaczymy według prostego wzoru:
Liczba_procesów_opóźnionych / Liczba_procesów_uruchomionych * 100
W celu odczytu wskaźnika normalnie powinniśmy wykonać oddzielnie powyższe zapytania. Jednak poprzez zastosowanie pewnego triku postaramy się to zrobić jednym zapytaniem. W pierwszym kroku zdefiniujemy widok odczytujący liczbę wszystkich wykonywanych zadań:
CREATE VIEW RUNNING_PROC_COUNT AS
SELECT
COUNT(*) AS PROCESS_COUNT
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = 0
W następnym kroku wykonamy zapytanie zwracające zadany wskaźnik.
SELECT
ROUND(COUNT(AI_ID)/ SUM(PROCESS_COUNT) * 100, 2) AS "Delayed tasks [%]"
FROM
V_ACTIVITY_INST ,
RUNNING_PROC_COUNT
WHERE
AI_FINISHED = 0 AND
AI_PLANNED_FINISH_DATE < CURRENT_DATE - 10
Ponieważ perspektywa RUNNING_PROC_COUNT zwraca zawsze 1 krotkę, zapytanie zwraca poprawny wskaźnik. Aby umożliwić wykonanie agregacji danych, wykonaliśmy sumę wartości zwracanych przez perspektywę RUNNING_PROC_COUNT równą zwracanej (jednej) krotce.
Raportowanie
W systemie docuRob®Workflow raportowanie umożliwia ekstrakcję danych dotyczących definicji i wykonania procesów w zadanej formie i szacie graficznej. Dane te są prezentowane w postaci raportu. Oprócz samej definicji raportu kluczowe jest przygotowanie zapytania dostarczającego dane (tak zwane źródło danych) oraz zdefiniowanie odpowiednich kryteriów selekcji raportu.
Poniżej podano kilka przykładów definicji źródeł danych do raportu bazujących na Repozytorium procesów. W celu wykorzystania przedstawionych zapytań najlepiej jest, aby zdefiniować je jako nowe perspektywy w Repozytorium procesów. Sortowanie na tych widokach należy wykonać bezpośrednio w definicji raportu (poza perspektywą).
Przykład nr 1
Cel: Statystyka pracy poszczególnych pracowników określona w terminach zadań przez nich wykonanych (zakończonych) w zadanym przedziale czasu. Raport powinien uwzględniać zastępstwa i móc być wykonany dla pracowników danej organizacji lub komórki organizacyjnej.
Realizacja: W celu zdefiniowania zapytania najpierw określmy odzyskiwane dane. Dane te będą reprezentowane poprzez poszczególne pola (kolumny) perspektyw dostępnych w Repozytorium procesów. Lista kolumn musi uwzględniać pola, które będą wyświetlane w raporcie lub są kryteriami selekcji dla tego raportu. W naszym przykładzie zakładamy, że w raporcie będzie wyświetlana nazwa rzeczywistego wykonawcy zadania i tak zwanego logicznego wykonawcy zadania, czyli osoby, która to zadanie miała wykonać. Innymi słowy będzie to informacja o zastępującym (kto rzeczywiście wykonał) i zastępowanym (kto miał to wykonać). Oprócz tych danych w raporcie powinna znaleźć się też dane o liczbie zadań wykonanych w zadanym okresie czasu.
Jeżeli chodzi o kryteria to zgodnie z wymaganiami przyjmujemy, że będą to atrybuty logicznego wykonawcy zadania reprezentowane poprzez atrybuty attr1 (identyfikator organizacji) i attr2 (identyfikator komórki organizacyjnej). Kolejnym kryterium będzie data zakończenia zadania – zliczać będziemy tylko zadania już zrealizowane. Ze względu na grupowanie danych nie dodamy kryteriów na daty do zapytania, inaczej grupowanie nie zadziałałoby.
Zapytanie implementujące nasze założenia jest następujące:
SELECT
AI_PERFORMER_NAME,
AI_PERFORMER_ATTR1,
AI_PERFORMER_ATTR2,
AI_LOG_PERFORMER_NAME,
AI_LOG_PERFORMER_ATTR1,
AI_LOG_PERFORMER_ATTR2,
COUNT(*)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = 1 AND
AI_STATUS = 1 AND
AI_FINISHED_DATE BETWEEN <data_od> AND <data_do>
GROUP BY
AI_PERFORMER_NAME,
AI_PERFORMER_ATTR1,
AI_PERFORMER_ATTR2,
AI_LOG_PERFORMER_NAME,
AI_LOG_PERFORMER_ATTR1,
AI_LOG_PERFORMER_ATTR2
UWAGA. Odejmowanie pomiędzy datami zaprezentowane w przykładzie działa na serwerze PostgreSQL. Dla innych serwerów może być potrzebne predefiniowanie tego wyrażenia. Daty oraz liczby rzeczywiste są takimi wartościami, że nie nadają się na elementy agregacji danych. Najczęściej agregacja dotyczy jedynie wybranych części takich wartości (np. dnia, miesiąca)
Przykład nr 2
Cel: Lista zadań opóźnionych o więcej niż zadana liczba dni. Informacja o wykonawcach zadania. uwzględnienia zastępstwa. Informacja o czasie utworzenia zadania, czasie rozpoczęcia wykonywania oraz planowanym czasie jego zakończenia. Uwzględnienie zadań w określonym zakresie czasu, dla pracowników danej organizacji i / lub komórki organizacyjnej.
Realizacja: W odróżnieniu od poprzedniego raportu, ten jest raportem filtrującym dane a nie agregującym je. Dane, które będą prezentowane w raporcie uwzględniają następujące kolumny: nazwa wykonawcy (logiczna i fizyczna), data utworzenia zadania, data rozpoczęcia zadania, planowana data zakończenia zadania. Aktualne opóźnienie, które na pewno znajdzie się w definicji raportu najlepiej jest zdefiniować jako pole wyliczane już w samej definicji na podstawie planowanej daty zakończenia i aktualnej daty generowania raportu.
Kryteria selekcji raportu są podobne do poprzednich kryteriów i uwzględniają atrybuty logicznego wykonawcy zadania reprezentowane poprzez atrybuty attr1 (identyfikator organizacji) i attr2 (identyfikator komórki organizacyjnej), data utworzenia zadania, i data rozpoczęcia zadania.
SELECT
AI_PERFORMER_NAME,
AI_PERFORMER_ATTR1,
AI_PERFORMER_ATTR2,
AI_LOG_PERFORMER_NAME,
AI_LOG_PERFORMER_ATTR1,
AI_LOG_PERFORMER_ATTR2,
AI_CREATED_DATE,
AI_STARTED_DATE,
AI_PLANNED_FINISH_DATE
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED = 0 AND
AI_PLANNED_FINISH_DATE < CURRENT_DATE - <zadana_liczba dni>
W polu <zadana_liczba_dni> należy wstawić odpowiednią datę zgodnie z formatem wspieranym przez bazę danych. W przypadku serwera PostgreSQL jest to data w formacie 'YYYY-MM-DD', np. '2008-09-23'.
Analiza obciążenia procesów
Głównym celem analizy procesów jest identyfikacja sytuacji wymagających poprawy. W celu identyfikacji takich sytuacji analizowane są dane pochodzące z wykonania procesów. Analiza jest najczęściej wykonywana na różnych typach procesów na raz. Ze względu na możliwą dużą ilość tych danych, analizę zawęża się do określonego przedziału czasu. Kolejnym krokiem następującym po analizie jest najczęściej propozycja poprawy procesu (ów) skutkująca uaktualnieniem definicji.
Poniżej zawarto kilka rzeczywistych przykładów będących siłą napędową takiej analizy.
Przykład 1 – Charakterystyka pracy pracowników – duża inercja w realizacji zadań
Cel: Jednym z elementów wymagających analizy dążącej do wykonania działań związanych z równoważeniem obciążenia jest identyfikacja wykonawców, u których zadania są rozpoczynane z dużym opóźnieniem w stosunku do momentu ich utworzenia.
Realizacja: Praktycznie przyjmuje się, że czas rozpoczęcia zadania w standardowym przypadku nie powinien przekraczać jednego dnia. Zapytanie będzie zapytaniem agregującym, gdzie podamy średni, minimalny i maksymalny czas pomiędzy utworzeniem zadania i jego rozpoczęciem. Będziemy filtrować wykonawców, u których średni taki czas przekracza 4 godziny. Celem uproszczenia, pod uwagę weźmiemy wszystkie zadania zakończone poprawnie.
SELECT
AI_PERFORMER_NAME,
AI_LOG_PERFORMER_NAME,
MIN(AI_STARTED_DATE-AI_CREATED_DATE),
AVG(AI_STARTED_DATE-AI_CREATED_DATE),
MAX(AI_STARTED_DATE-AI_CREATED_DATE)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED= 1 AND
AI_STATUS = 1
GROUP BY
AI_PERFORMER_NAME,
AI_LOG_PERFORMER_NAME
HAVING
AVG(AI_STARTED_DATE-AI_CREATED_DATE) > 1
W celu odfiltrowania wykonawców, dla których średni czas różnicy pomiędzy utworzeniem a rozpoczęciem zadania jest większy niż jeden dzień wykorzystano klauzulę HAVING.
Przykład 2 – Charakterystyka pracy pracowników – długie kolejki zadań
Cel: Identyfikacja wykonawców, u których czas oczekiwania zadań w kolejce do realizacji stanowi więcej niż 50% całego czasu realizacji zadania (od momentu utworzenia do momentu zakończenia).
Realizacja: W tym wypadku będziemy sprawdzać zadania zakończone, dla wykonawców, u których średni czas oczekiwania w kolejce jest większy niż 50% średniego czasu realizacji całego zadania.
SELECT
AI_PERFORMER_NAME,
AI_LOG_PERFORMER_NAME,
AVG(AI_STARTED_DATE-AI_CREATED_DATE),
AVG(AI_FINISHED_DATE - AI_CREATED_DATE)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED= 1 AND
AI_STATUS = 1
GROUP BY
AI_PERFORMER_NAME,
AI_LOG_PERFORMER_NAME
HAVING
AVG(AI_STARTED_DATE-AI_CREATED_DATE) * 2 > AVG(AI_FINISHED_DATE - AI_CREATED_DATE)
Próg 50% zdefiniowano jako połowę wartości całego czasu wykonania procesu oraz zastosowano klauzulę HAVING do filtracji agregowanych danych.
Przykład 3 – Charakterystyka pracy pracowników – wykrywanie bezczynności
Cel: Identyfikacja wykonawców, którzy przez okres czasu dłuższy niż zdefiniowany próg nie wykonują zadań w systemie.
Realizacja: Praktycznie, sprawdzenie dotyczy zadań dystrybucji, gdzie nie jest wymagany długi czas wykonywania zadań. W ten sposób unikamy błędnego wskaźnika, który podawałby niewłaściwe dane w przypadku zadań wymagających sporej pracy poza procesem (np. przygotowanie dokumentu decyzji, spotkania i telekonferencje, itp.). Przestoje w wykonywaniu zadań będą liczone w terminach daty zakańczania zadań.
SELECT
A.AI_PERFORMER_NAME as "Osoba",
A.AI_STARTED_DATE as "Punkt startowy",
B.AI_STARTED_DATE as "Kolejny punkt",
B.AI_STARTED_DATE - A.AI_STARTED_DATE as "Czas przestoju [HH:MM:SS]"
FROM
V_ACTIVITY_INST as A, V_ACTIVITY_INST as B
WHERE
A.AI_STARTED_DATE >= <data_od> AND
A.AI_STARTED_DATE <= <data_do> AND
A.AI_PERFORMER_ID <> '-1' AND -- nie wykonawca automatyczny (system)
A.AI_STARTED_DATE <
(SELECT MIN(C.AI_STARTED_DATE)
FROM V_ACTIVITY_INST as C
WHERE C.AI_STARTED_DATE > A.AI_STARTED_DATE AND
C.AI_PERFORMER_ID = A.AI_PERFORMER_ID)
- '25min'::interval AND
B.AI_STARTED_DATE =
(SELECT MIN (C.AI_STARTED_DATE)
FROM V_ACTIVITY_INST as C
WHERE C.AI_STARTED_DATE > A.AI_STARTED_DATE AND
C.AI_PERFORMER_ID = A.AI_PERFORMER_ID) AND
B.AI_PERFORMER_ID = A.AI_PERFORMER_ID
ORDER BY
"Osoba", "Punkt startowy", "Czas przestoju [HH:MM:SS]"
Algorytm działania jest następujący:
- weź zadanie z określonego zakresu czasu wykonywane (lub wykonane) przez dowolnego pracownika organizacji (ale nie system wykonujący zadania automatyczne ). jest to krotka w obiekcie A.
- następnikiem wybranego zadania musi być zadanie najbliższe w czasie do tego zadania (agregacja poprzez funkcje MIN oraz warunek na czas rozpoczęcia (krotka w obiekcie C), wykonywane przez tego samego pracownika). Dodatkowo przetwarzaj (krotka z obiektu A) tylko te zadania, dla których następnik jest oddalony w czasie więcej niż 25 minut.
- jako rezultat wykonania zwracane jest także zadanie będące następnikiem analizowanego zadania (krotka w obiekcie B). W tym celu ponownie wybierz zadanie kolejne do zadania analizowanego w sposób analogiczny jak opisano powyżej.
Przykład 4 – Charakterystyka pracy organizacji
Cel: Zrozumienie charakterystyki pracy organizacji wyrażonej w terminach liczby zadań utworzonych w danym okresie czasu. Po uwagę brane są poszczególne godziny pracy oraz dni robocze w trakcie tygodnia. Informacja taka pozwala na lepsze planowanie wykorzystania zasobów informatycznych, na przykład w momentach tak zwanych pików wykorzystania systemu wykonywanie działań automatycznych oraz administracji systemu powinno być zredukowane do minimum.
Realizacja: Informacje o charakterystyce pracy będą zbierane na podstawie danych o utworzonych zadaniach w danym okresie czasu. Grupowanie i zliczanie zadań będzie wykonane na podstawie daty (rok, miesiąc, dzień) oraz godziny.
SELECT
EXTRACT(DAY FROM AI_FINISHED_DATE) as "Dzień",
EXTRACT(HOUR FROM AI_FINISHED_DATE)as "Godzina",
COUNT(*) as "Liczba zadań zakończonych"
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED_DATE BETWEEN <data_od> AND <data_do>
GROUP BY
EXTRACT(DAY FROM AI_FINISHED_DATE),
EXTRACT(HOUR FROM AI_FINISHED_DATE)
ORDER BY
EXTRACT(DAY FROM AI_FINISHED_DATE),
EXTRACT(HOUR FROM AI_FINISHED_DATE)
Do wyciągnięcia dnia i godziny wykorzystano funkcję EXTRACT, specyficzną dla serwera PostgreSQL. Dla innych serwerów wymagane będzie użycie innych funkcji.
Przykład 5 – Charakterystyka pracy komórek organizacyjnych
Cel: Zrozumienie charakterystyki pracy komórki organizacyjnej wyrażonej w terminach liczby zadań utworzonych w danym okresie czasu. Po uwagę brane są poszczególne godziny pracy oraz dni robocze w trakcie tygodnia. Informacja taka pozwala na lepsze planowanie wykorzystania zasobów informatycznych, na przykład w momentach tak zwanych pików wykorzystania systemu wykonywanie działań automatycznych oraz administracyjnych powinno być zredukowane do minimum.
Realizacja: Informacje o charakterystyce pracy będą zbierane na podstawie danych o utworzonych zadaniach w danym okresie czasu. Grupowanie i zliczanie zadań będzie wykonane na podstawie daty (rok, miesiąc, dzień) oraz godziny.
SELECT
EXTRACT(DAY FROM AI_FINISHED_DATE) as "Dzień",
EXTRACT(HOUR FROM AI_FINISHED_DATE)as "Godzina",
AI_PERFORMER_ATTR1 as "Organizacja",
AI_PERFORMER_ATTR2 as "Komórka organizacyjna",
COUNT(*) as "Liczba zadań zakończonych"
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED_DATE BETWEEN <data_od> AND <data_do>
GROUP BY
EXTRACT(DAY FROM AI_FINISHED_DATE),
EXTRACT(HOUR FROM AI_FINISHED_DATE),
AI_PERFORMER_ATTR1,
AI_PERFORMER_ATTR2
ORDER BY
AI_PERFORMER_ATTR1,
AI_PERFORMER_ATTR2,
EXTRACT(DAY FROM AI_FINISHED_DATE),
EXTRACT(HOUR FROM AI_FINISHED_DATE)
W pola <data_od> oraz <data_do> należy wpisać konkretne wartości dat zgodnie z formatem wspieranym przez serwer bazy danych.
Identyfikacja sytuacji wyjątkowych
Niekiedy procesy są wykonywane niepoprawnie. Dzieje się to zazwyczaj z powodu błędnej definicji procesu lub jego otoczenia. W przypadku otoczenia procesu sytuacje wyjątkowe są związane z niedostępnością lub błędami wykonywanych usług, wyznaczanymi wykonawcami i przetwarzanymi danymi. Procesy i ich zadania wykonywane niepoprawnie są wstrzymywane lub przerywane. Po zaistnieniu takich sytuacji są one analizowane a rezultaty takiej analizy stanowią podstawę do poprawy lub optymalizacji procesu.
Przykład nr 1
Cel: Identyfikacja czynności, które są najczęściej wstrzymywane.
Realizacja: W celu wykonania tego zadania wykorzystamy informacje o statusie zadania. Jeżeli zadanie zostało wstrzymane, to jego status jest równy 4. Wyszukamy więc wszystkie zadania o takim statusie i pogrupujemy je według czynności, której instancjami są te zadania.
SELECT
AI_AD_NAME,
COUNT(*)
FROM
V_ACTIVITY_INST
WHERE
AI_FINISHED= 1 AND
AI_STATUS = 4
GROUP BY
AI_AD_NAME
ORDER BY
COUNT(*) DESC
Przykład nr 2
Cel: Identyfikacja skali procesów przerywanych z podziałem na poszczególne typy i wersje procesów.
Realizacja: W celu wykonania tego zadania wykorzystamy informacje o statusie procesów. Jeżeli proces został przerwany, to jego status jest równy 2. Zliczenie takich procesów wykonamy po nazwie definicji procesu i numerze wersji.
SELECT
PD_NAME,
PD_VERSION,
COUNT(*)
FROM
V_PROCESS_INST, V_PROCESS_DEF
WHERE
PI_FINISHED= 1 AND
PI_STATUS = 4 AND
PD_ID = PI_PD_ID
GROUP BY
PD_NAME,
PD_VERSION
ORDER BY
COUNT(*) DESC
Wydajność
Przy dużej ilości danych, w celu wykonania zapytań na Repozytorium procesów kluczowym jest ustawienie odpowiednich warunków zawężających. Mają one duży wpływ na szybkość wyszukiwania.
Dany warunek, zdefiniowany na konkretnym atrybucie (atrybutach) ma dwa efekty zmniejszania czasu realizacji zapytania:
- znacząco redukuje liczbę przetwarzanych rekordów,
- umożliwia wykorzystanie indeksu do szybszego wyszukiwania danych.
Najszybsze zapytania dotyczą wyszukiwania danych po kluczach, zarówno głównym jak i obcych. Ponieważ wszystkie klucze są indeksowane, odpowiedź systemu jest natychmiastowa.
Aby pomóc konstruować efektywne zapytania, w poniższej tabeli podano zestaw wskazówek dotyczących najpopularniejszych pól wykorzystywanych to wyszukiwania danych w Repozytorium procesów.
| Nazwa kolumny | Jak jest indeksowana | Jak wpływa na zawężenie liczby zwracanych rekordów | Dodatkowe komentarze |
|---|---|---|---|
| PI_CREATED_DATE | Zalecany do wyszukiwania zakresowego, tzn. od-do. | Znacząco. Zaleca się ustawienie tego kryterium na określony zakres, najlepiej dnia, tygodnia, miesiąca. | |
| PI_STATUS | Zalecany do podawania konkretnej wartości lub listy wartości. Najczęściej wyszukiwanie zadań utworzonych ale nie rozpoczętych. | Znacząco. | Zaleca się, aby, o ile jest to możliwe, to kryterium zawsze było uwzględnione w zapytaniu. |
| AI_CREATED_DATE | Zalecany do wyszukiwania zakresowego, tzn. od-do. | Znacząco. Zaleca się ustawienie tego kryterium na określony zakres, najlepiej dnia, tygodnia, miesiąca. | |
| AI_START_DATE | Zalecany do wyszukiwania zakresowego, tzn. od-do. | Znacząco. Zaleca się ustawienie tego kryterium na określony zakres, najlepiej dnia, tygodnia, miesiąca. | Jeżeli jest ustawione kryterium na datę utworzenia zadania, to niniejsze kryterium daje minimalne przyspieszenie. |
| AI_FINISHED_DATE | Zalecany do wyszukiwania zakresowego, tzn. od-do. | Znacząco. Zaleca się ustawienie tego kryterium na określony zakres, najlepiej dnia, tygodnia, miesiąca. | Jeżeli jest ustawione kryterium na datę utworzenia zadania lub rozpoczęcia, to niniejsze kryterium daje minimalne przyspieszenie. |
| AI_FINISHED | Zalecany do podawania konkretnej wartości. Najczęściej wyszukiwanie zadań wykonywanych. | Znacząco, ponieważ liczba zadań przetwarzanych jest znikoma w stosunku do wszystkich zadań składowanych w Repozytorium. | Zaleca się, aby, o ile jest to możliwe, to kryterium zawsze było uwzględnione w zapytaniu. |
| AI_STATUS | Zalecany do podawania konkretnej wartości lub listy wartości. Najczęściej wyszukiwanie zadań utworzonych ale nie rozpoczętych. | Znacząco, podobnie jak status zakończenia zadania. | Zaleca się, aby, o ile jest to możliwe, to kryterium zawsze było uwzględnione w zapytaniu. Jeżeli jest ustawione kryterium na status zakończenia, kryterium to nie wprowadza znaczącego przyspieszenia – wyjątek – zadania przerwane. |
Tabela 9. Wskazówki dotyczące wykorzystania pól zawartych w Repozytorium procesów
Modelowanie obciążenia pracą (ang. workload)
Podstawowym zasobem procesów biznesowych zarządzanych na platformie docuRob®WorkFlow są pracownicy organizacji wykonujący zadania w procesach. Modelowanie obciążenia pracą jest prowadzone z perspektywy zadań procesów wykonywanych przez uprawnionych użytkowników posiadających odpowiednie umiejętności (kompetencje) pełniących role przyznane im w ramach danego procesu lub procesów.
Zależnie od rodzaju działalności objętej procesami biznesowymi role mogą być przyznawane w kontekście struktury organizacyjnej i odpowiednio mapowane na definicje procesów. W diagramie BPMN role uczestników procesu są prezentowane w odpowiednich torach (ang. swimlane) lub oznaczane przydzielonymi im kolorami. Ta druga metoda prowadzi do znacznie bardziej czytelnych graficznych modeli procesów.
Zbór wykonawców zadania procesu pełniących powiązaną z nim rolę może zawierać dynamicznie wyznaczane podzbiory wykonawców wynikające z konieczności uwzględnienia dodatkowych atrybutów, na przykład kompetencji.
Przykładem może być model procesu wydawniczego gdzie w ramach roli redaktor musimy uwzględnić także specjalizację naukową i znajomość języka w którym napisane jest oceniane opracowanie.
W ramach projektowania lub reorganizacji konfiguracji ról uczestników procesów pomocne jest zastosowanie metodyki i narzędzi OLAP (online analytical processing) natomiast do projektowania lub optymalizacji istniejących procesów, gdzie potrzebna jest informacja dotycząca wpływu decyzji projektanta na miary obciążenia pracą, dostarczamy wsparcie projektanta dostępne w ramach narzędzia projektowania procesów platformy docuRob®WorkFlow.
Analiza wielowymiarowego modelu wykonania procesów
Wielowymiarowa analiza modelu wykonania procesów wymaga dostępu do odpowiednio przygotowanej struktury logów wykonanych zadań procesów biznesowych eksploatowanych w danej organizacji umożliwiającej zaprojektowanie i implementację schematu kostki OLAP oraz wykonywanych w oparciu o ten schemat zapytań analitycznych.
Tak przygotowane środowisko pozwala kierownictwu i odpowiednim właścicielom procesów na bieżącą analizę obciążenia pracą i występujących w tym obszarze potencjalnych anomalii. Strukturę klas obiektów przygotowanego do przetwarzania logu wykonania procesów przedstawia Rysunek 7 a schemat kostki OLAP umożliwiającej analizę zawiera Rysunek 8.
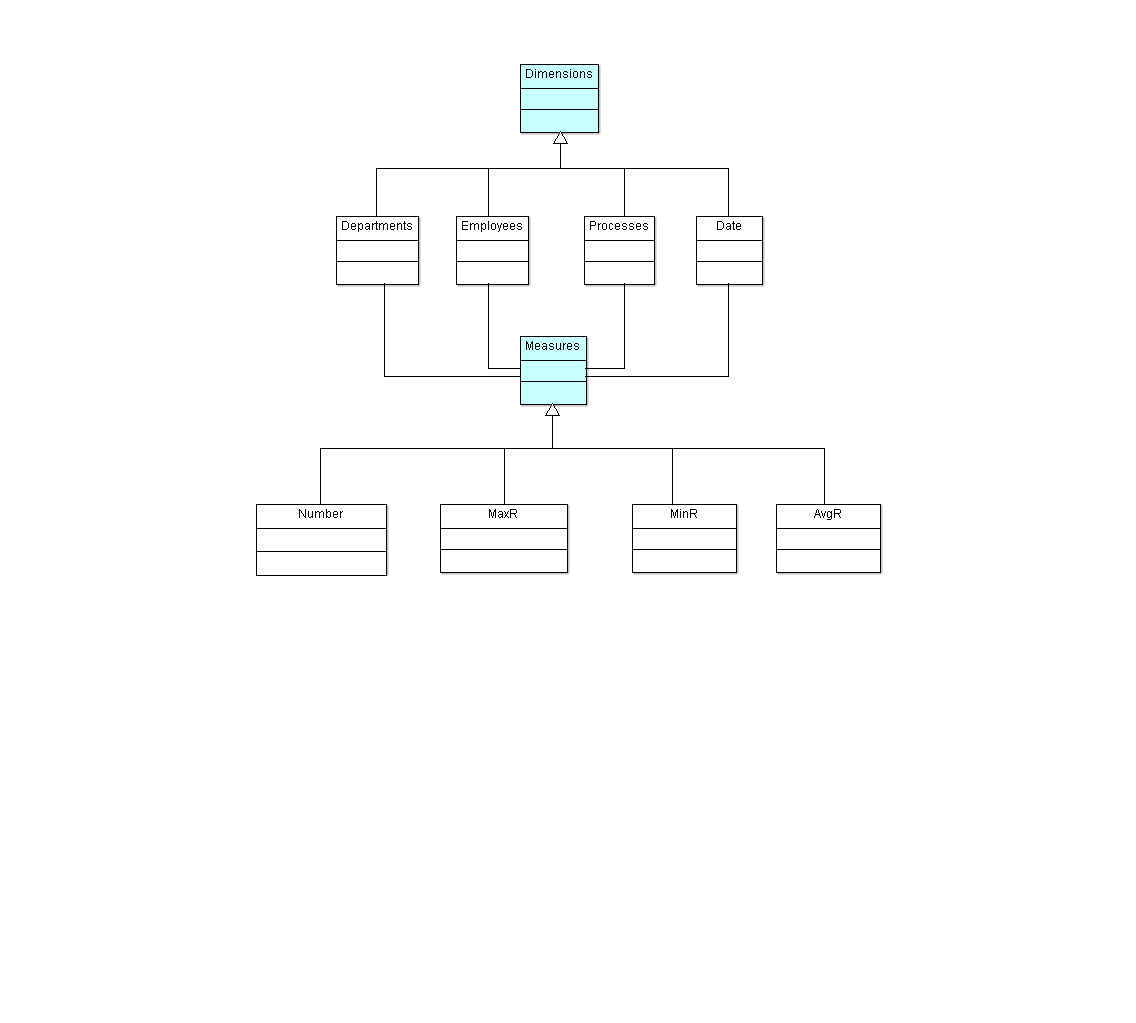
Rysunek 7. Diagram klas wielowymiarowego modelu analizy logu zdarzeń (MDX)
Zapytanie w języku MDX w którego wyniku powstaje rozwinięty widok analityczny zawierający kontrolki pozwalające na dynamiczne rozwijanie i zwijanie odpowiednich fragmentów modelu przedstawia Rysunek 9. Zapytanie MDX materializujący widok analityczny na dolnym ekranie Rysunek 10. Zapytanie materializuje interfejs analizy przedstawiony na dolnym ekranie Rysunek 10. Zgodnie z przyjętym modelem struktury logów procesów na poszczególnych poziomach modelu są udostępniane następujące odpowiednio agregowane miary:
- Liczba instancji zadań – liczba zadań wykonanych na danym poziomie agregacji
- MaxR maksymalny czas rezydencji zadania – maksymalny czas rezydencji zadania(1) na danym poziomie agregacji
- MinR minimalny czas rezydencji zadania na danym poziomie agregacji
- AvgR średni czas rezydencji zadania na danym poziomie agregacji
(1) Czas rezydencji obejmuje czas w kolejce + czas wykonania zadania
Agregacja obejmuje wartości miar od poziomu indywidualnego uczestnika zadania do całej organizacji. Przejścia pomiędzy poziomami agregacji modelu są wykonywane przez użytkowników modelu przez odpowiednie kontrolki +
Dolny ekran Rysunek 10 pokazuje rozwinięty Proces obsługi korespondencji w komórce zagregowany na poziomie rodzaju zadania . Ten poziom agregacji obejmuje wszystkich pracowników danej komórki organizacyjnej.
Schema name="docman">
<Cube name="OfficeObjects WorkFlow Processes" cache="true" enabled="true">
<Table name="v_cz_finished_manual" schema="docman"/>
<Dimension name="Departments" foreignKey="icz_podmiot_attr2">
<Hierarchy hasAll="true" allMemberName="All Departments" primaryKey="child_id">
<Table name="as_zw_komorek_aktywne" schema="docman"/>
<Level name="Department" uniqueMembers="true" column="child_id" nameColumn="name" type="Numeric" parentColumn="parent_id" nullParentValue="0">
<Closure parentColumn="parent_id" childColumn="child_id">
<Table name="as_zw_komorek_aktywne_closure"/>
</Closure>
</Level>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" name="Employees">
<Hierarchy hasAll="true" allMemberName="All Employees">
<Level name="Employee" column="icz_podmiot_nazwa" type="String" uniqueMembers="true" levelType="Regular" hideMemberIf="Never"/>
</Hierarchy>
</Dimension>
<Dimension type="StandardDimension" foreignKey="icz_id" name="Processes">
<Hierarchy hasAll="true" allMemberName="All Processes" primaryKey="icz_id" primaryKeyTable="tb_act_inst_finished_manual">
<Join leftAlias="tb_act_inst_finished_manual" leftKey="icz_pp_id" rightAlias="tb_process_def" rightKey="pd_id">
<Table name="tb_act_inst_finished_manual" schema="docman"/>
<Table name="tb_process_def" schema="docman"/>
</Join>
<Level name="Process" table="tb_process_def" column="pd_name" type="String" uniqueMembers="true" levelType="Regular" hideMemberIf="Never"/>
<Level name="Activity" table="tb_act_inst_finished_manual" column="icz_name" type="String" uniqueMembers="true" levelType="Regular" hideMemberIf="Never"/>
<Level name="Instance" table="tb_act_inst_finished_manual" column="icz_id" type="String" uniqueMembers="true" levelType="Regular" hideMemberIf="Never"/>
</Hierarchy>
</Dimension>
<Dimension type="TimeDimension" foreignKey="icz_data_rozp" name="Date">
<Hierarchy name="YQMD" hasAll="true" allMemberName="All Dates" primaryKey="time_stp">
<Table name="date_time" schema="docman"/>
<Level name="Year" column="year" type="Numeric" uniqueMembers="true" levelType="TimeYears" hideMemberIf="Never"/>
<Level name="Quarter" column="quoter" type="Numeric" uniqueMembers="false" levelType="TimeQuarters" hideMemberIf="Never" captionColumn="quoter_label"/>
<Level name="Month" column="month" type="Numeric" uniqueMembers="false" levelType="TimeMonths" hideMemberIf="Never" captionColumn="month_label"/>
<Level name="Day" column="day" type="Numeric" uniqueMembers="false" levelType="TimeDays" hideMemberIf="Never"/>
</Hierarchy>
</Dimension>
<Measure name="Number" column="icz_finished" datatype="Integer" aggregator="count" visible="true"/>
<Measure name="MaxR" column="icz_residence_time" datatype="Numeric" formatString="#,###0.00" aggregator="max" visible="true"/>
<Measure name="MinR" column="icz_residence_time" datatype="Numeric" formatString="#,###0.00" aggregator="min" visible="true"/>
<Measure name="AvgR" column="icz_residence_time" datatype="Numeric" formatString="#,###0.00" aggregator="avg" visible="true"/>
</Cube>
</Schema>
Rysunek 8. Wielowymiarowy schemat modelu analizy logu (MDX)
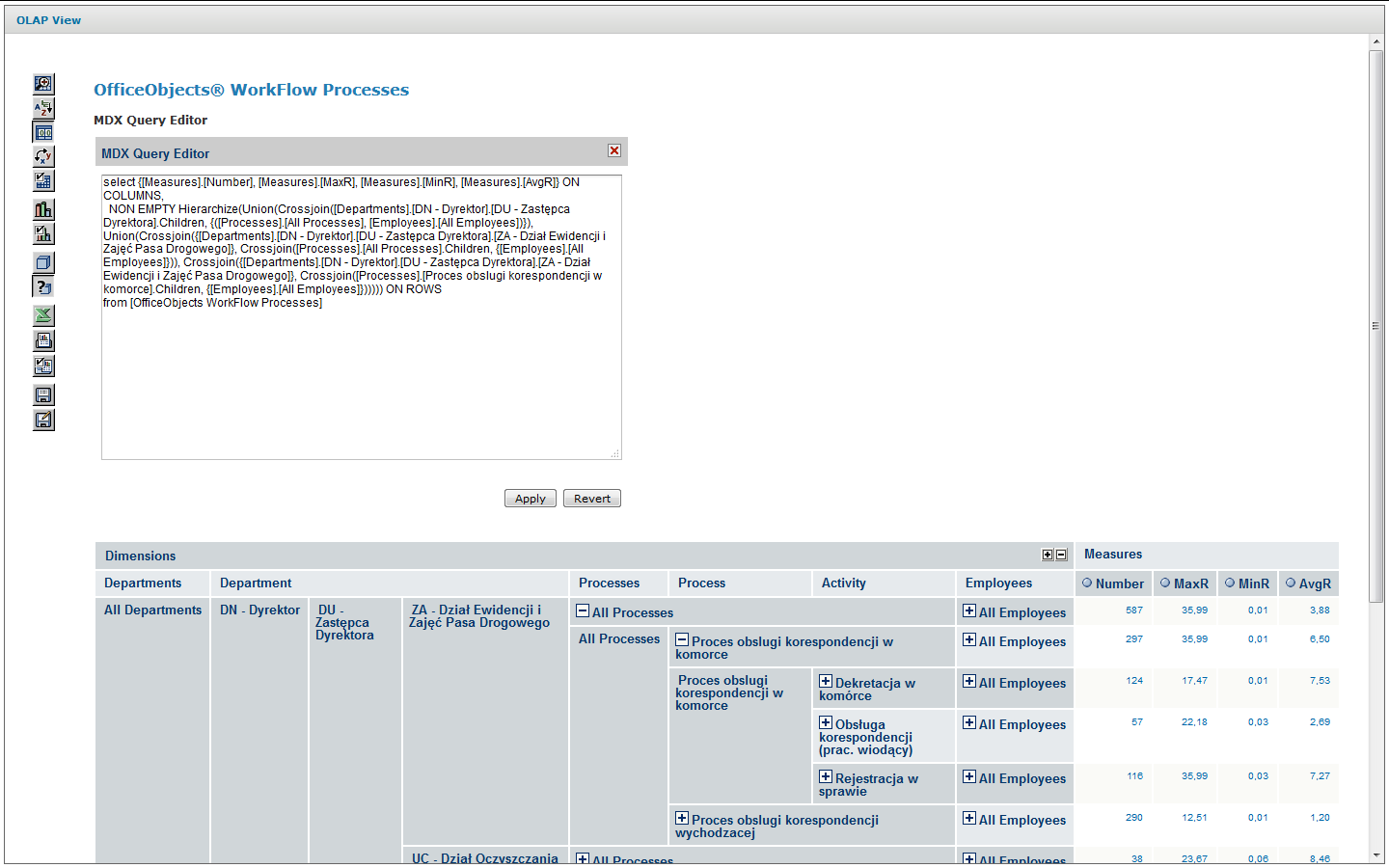
Rysunek 9. Zapytanie MDX materializujący widok analityczny na dolnym ekranie Rysunek 10
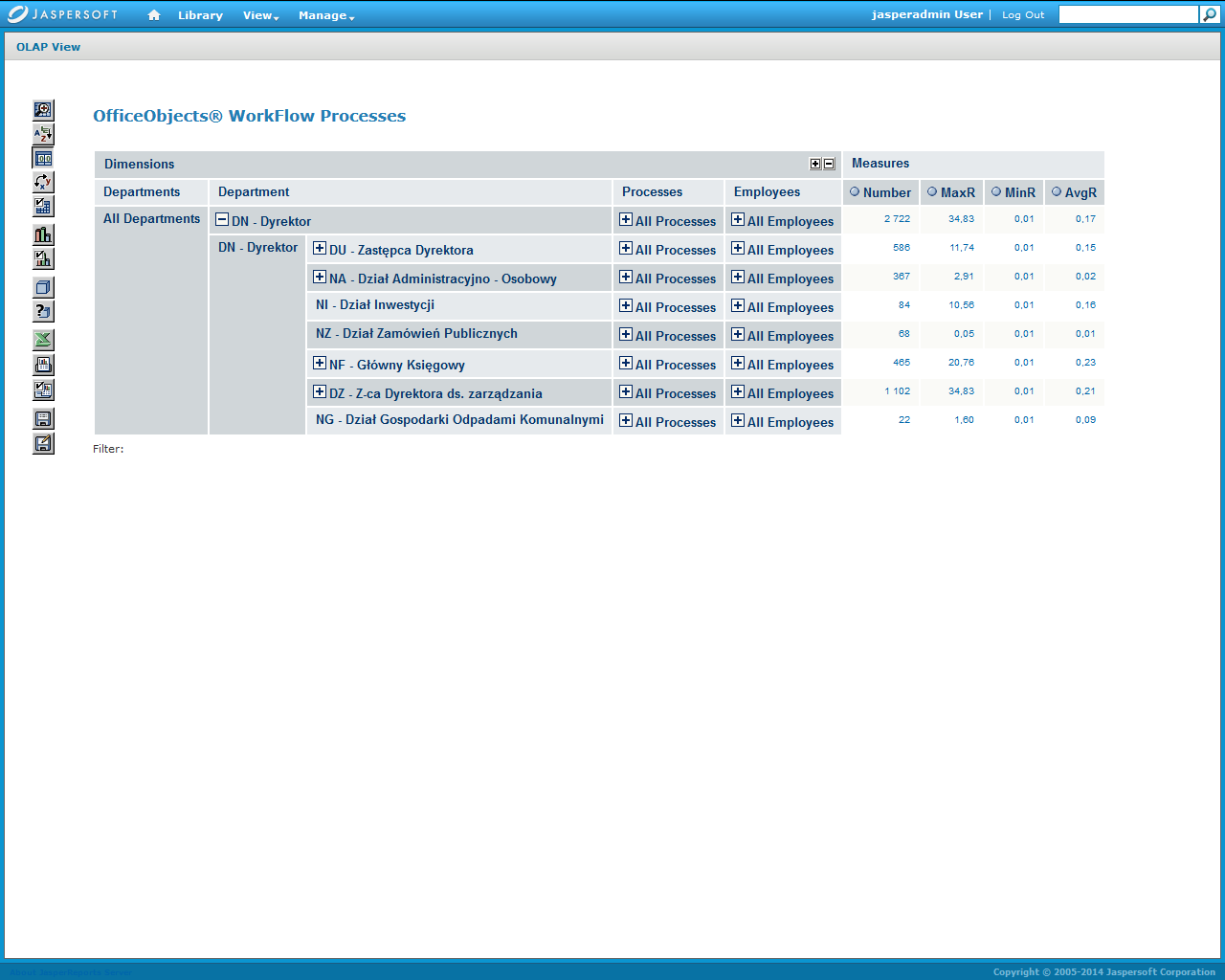
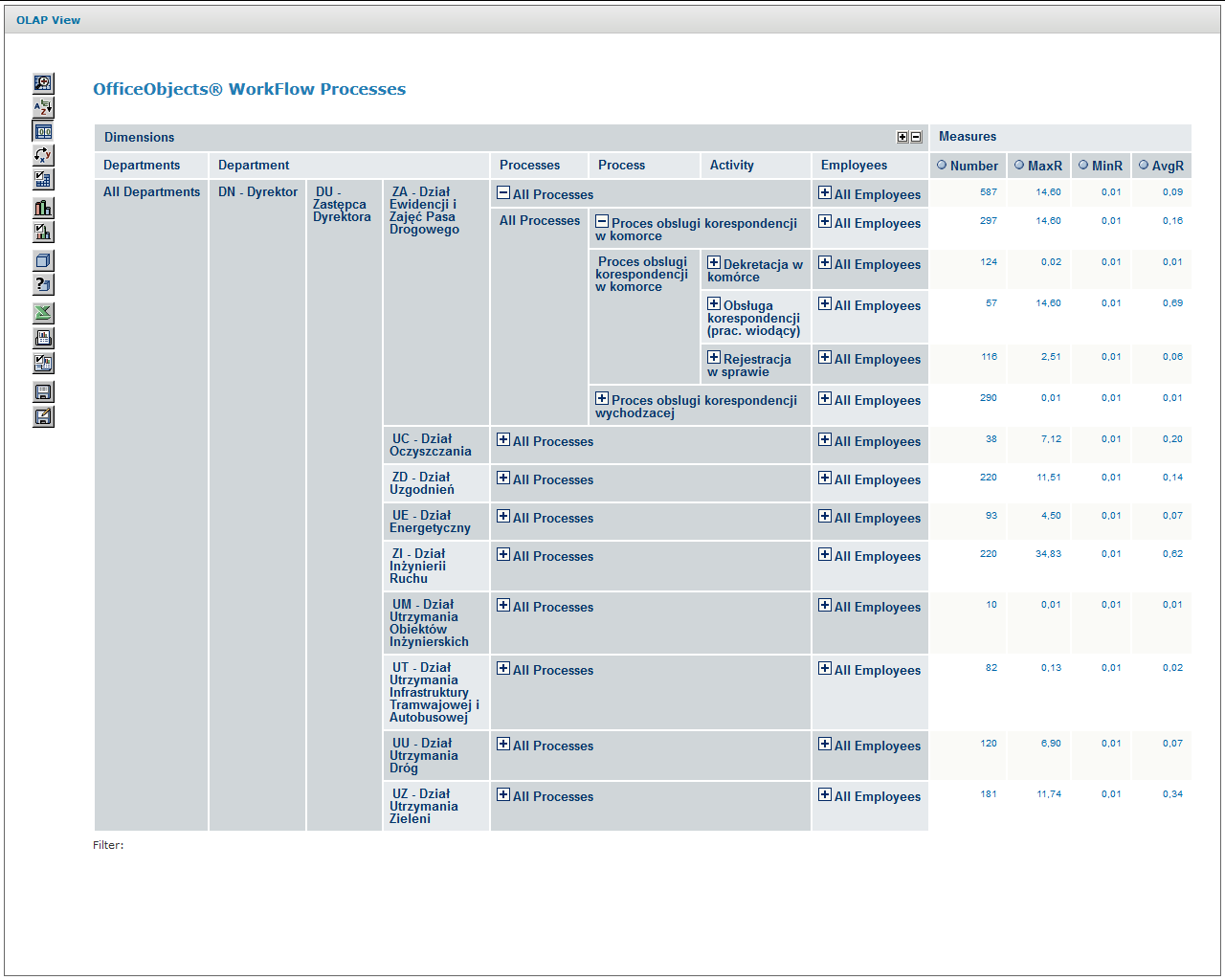
Rysunek 10. Ekrany wejściowy i rozwinięty wielowymiarowej analizy logów procesów
Przedstawioną powyżej analizę obciążeń wykonano w oparciu o platformę Mondrian_3.0 wykorzystującą język Multidimensional Expressions (MDX) oraz cienkiego klienta jPivot służącego do prezentacji i manipulacji graficznego interfejsu użytkownika.
Analityczny model symulacji wykonania procesów
Monitorowanie wykonania procesów biznesowych, zarówno na poziomie pojedynczych instancji jak i na poziomie OLAP, może dostarczyć wystarczających informacji dla analizy obciążenia poszczególnych grup użytkowników występujących w różnych rolach jako wykonawcy zadań. Uzyskane w ten sposób parametry obciążenia pracą (ang. workload) pozwalają zazwyczaj na wprowadzanie odpowiednich korekt modeli procesów i rozwiązania problemów „wąskich gardeł”.
W praktyce mamy również do czynienia z koniecznością prowadzenia analizy ex ante w przypadku konieczności wstępnej weryfikacji nowoprojektowanych procesów biznesowych krytycznych z punktu widzenia generowanych przez nie obciążeń pracą lub gdy musimy zareagować na istotne zmiany charakterystyki obciążenia pracą występujące w odniesieniu do istniejących procesów.
Przykładem tego drugiego przypadku może być przewidywana zmiana proporcji typów transakcji obsługiwanych przez poszczególne role użytkowników w ramach jednego lub kilku powiązanych typów procesów, które występują współbieżnie w ramach scenariuszy przetwarzania.
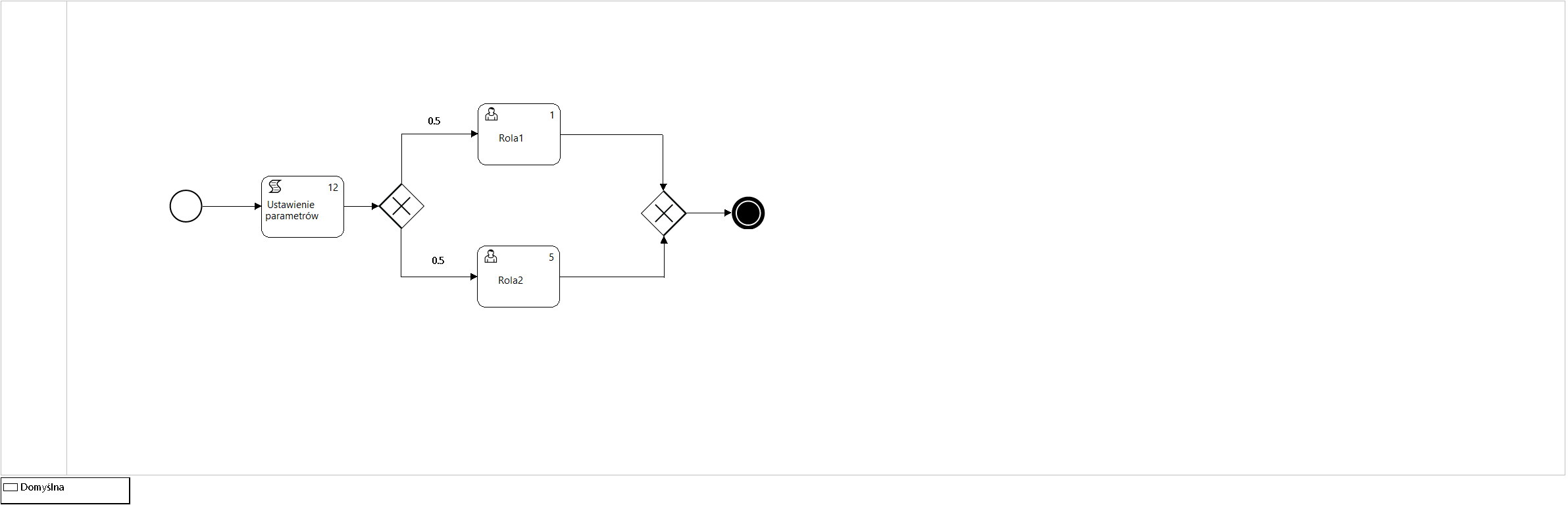
Rysunek 11. Model procesu P12_Symulacja3
Parametry obciążenia pracą obejmują wartości takich miar jak:
- Średnia liczba przetwarzanych współbieżnie instancji procesów
- Liczba wykonań (wizyt) zadań instancji procesów
- Średni czas obsługi zadania przez wybranego wykonawcę
Parametry zasobów ludzkich procesu obejmują takie wartości jak:
- Model ról wykonawców zadań określony dla danego typu procesu
- Liczność zbioru użytkowników w ramach każdej z ról
- Współczynnik kosztu wykonania danego zadania
Liczba wykonań zadań jest wyliczana na podstawie probabilistycznego modelu przepływów procesu, przy czym ten parametr jest używany wyłącznie dla czynności wykonywanych przez użytkowników (typ Użytkownik lub Ręczna) na podstawie podanych w przepływach pomiędzy czynnościami modelu prawdopodobieństwa przepływu.
Model procesu P12_Symulacja3, który jest wykorzystany w przykładzie przybliżonej analizy średnich wartości (ang. mean value analysis (MVA)) dla zamkniętej sieci kolejek (ang. closed queueing network) przedstawia Rysunek 11 a interfejsy służące do jego parametryzacji przedstawia Rysunek 12 jako zbiór ekranów narzędzia projektowania procesów platformy docuRob®WorkFlow.
Parametry podane w zakładce Symulacja opisu czynności podajemy liczbę wykonawców należących do zbioru potencjalnych wykonawców roli, to jest zbioru pracowników wybranych na podstawie wyrażenia przypisania wykonawców (ang. work participant assignment) BPQL. Zadania oczekujące w kolejce są przypisywane wszystkim wskazanym potencjalnym wykonawcom poprzez umieszczenie ich odpowiednio w listach zadań. Po pobraniu zadania przez wykonawcę jest ono usuwane z pozostałych list zadań. Pokazany przykład definicji wskazuje na 4 wykonawców czynności Rola2 co pozawala na modelowanie współbieżnej pracy wykonawców tego zadania a efektem jest odpowiednie obniżenie czasu rezydencji w kolejce.
W metadanych przepływu określa się jego prawdopodobieństwo a suma prawdopodobieństw dla wszystkich przepływów wychodzących danej czynności musi być równa 1.
Tabela 10 prezentuje podzbiór wartości miar obciążenia przybliżonego algorytmu MVA otrzymanych w wyniku 5 scenariuszy wykonanych dla modelu procesu pokazywanego na Rysunku 11. Zgodnie z przyjętym algorytmem modelującym kolejki zadań są wyliczane wyłącznie dla zadań wykonywanych przez użytkowników. Kolorem zielonym oznaczamy wartości wprowadzane jako parametry wejściowe algorytmu MVA pozostałe wartości są wynikiem obliczeń. Wartości wynikowe są liczbowe.
Ponieważ wykonywane współbieżnie instancje procesu P12_Symulacja3 zawierają 2 alternatywnie wybierane czynności wykonywane przez użytkowników należących do jednej z dwóch ról (Rola1 lub Rola2) i wykonują zawsze 20 współbieżnych instancji procesów to suma liczności obu kolejek wynosi ~20 (różnice na dalszych miejscach dziesiętnych wynikają z zaokrągleń). Jeżeli w modelu procesu wystąpi pętla to powtórzenia czynności są również uwzględniane. Liczba współbieżnych instancji procesów razem z prawdopodobieństwem przepływów determinuje liczność kolejek modelu.
Rysunek 13 prezentuje graficzną postać wybranych wartości wynikowych jednego z wykonanych scenariuszy modelu MVA. Liczba wizyt jest prezentowana dla wszystkich czynności natomiast nie biorą one udziału w obliczeniach modelu kolejek. Parametry kolejek są wyrażane jako liczba zadań i czas rezydencji (ang. residence time). Wartość czas rezydencji obejmuje liczbę zadań w kolejce plus zadanie bieżąco wykonywane.
Przedstawiony przykład analizy MVA dla zamkniętej sieci kolejek ilustruje wpływ zmian charakterystyki obciążeń, która może wynikać ze zmiany częstotliwości typów realizowanych usług. Taka zmiana powoduje zwykle modyfikację prawdopodobieństw przepływów, a tym samym zmianę liczby wizyt do poszczególnych czynności.
Likwidowanie wąskich gardeł polega na próbach zrównoważenia liczności kolejek a tym samym wyrównania czasów rezydencji dla poszczególnych zadań. Z podsumowania wyników w Tabeli 10 widać silne odziaływanie długości kolejek na wynikowe parametry scenariuszy.
Ponieważ czasy wykonania poszczególnych zadań są parametrem wejściowym, którego wartość można ustalić w oparciu o analizę przetwarzanych bieżąco procesów, to szukając optymalizacji możemy albo manipulować licznościami zbiorów wykonawców dostępnych w ramach poszczególnych ról albo podjąć próbą zmiany modelu procesu.
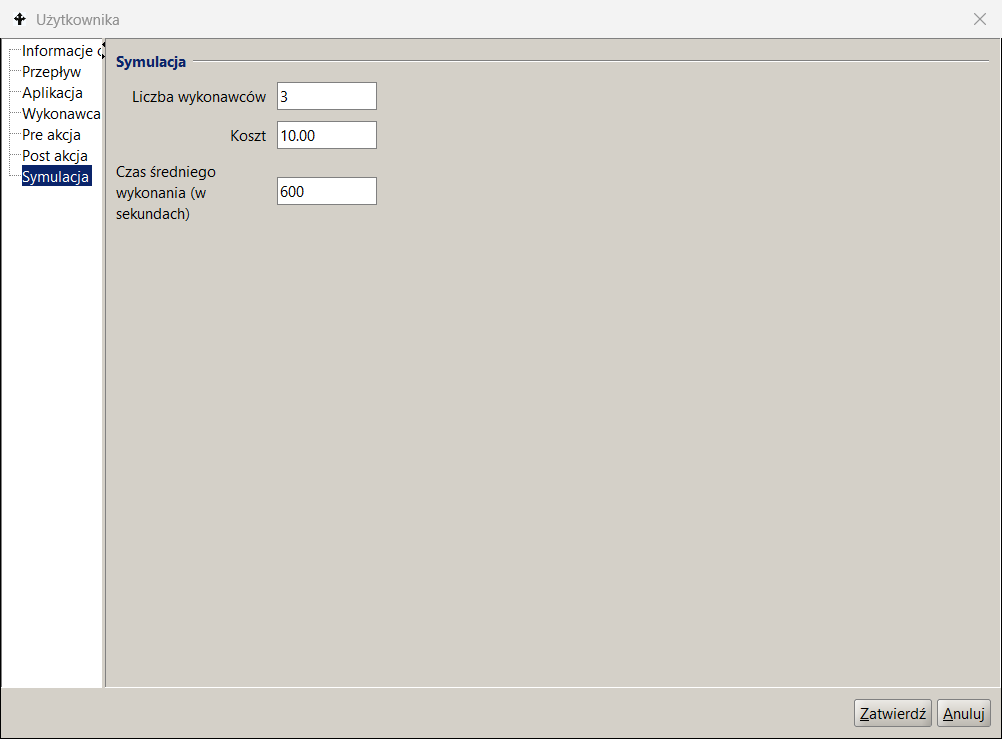
Zadanie Rola 1
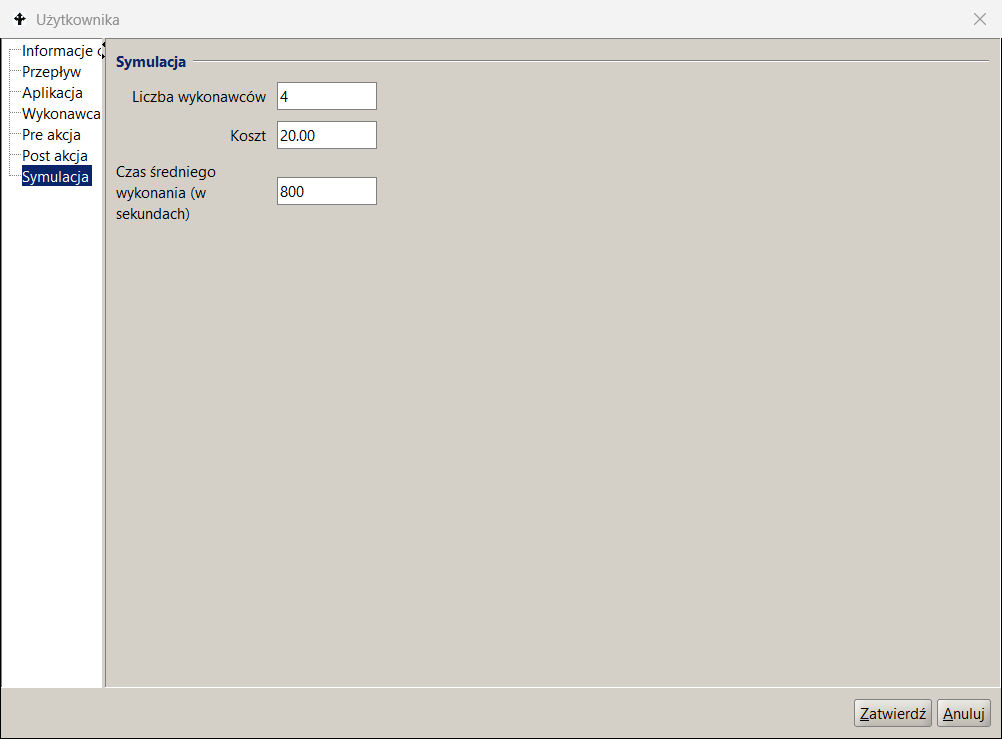
Zadanie Rola2
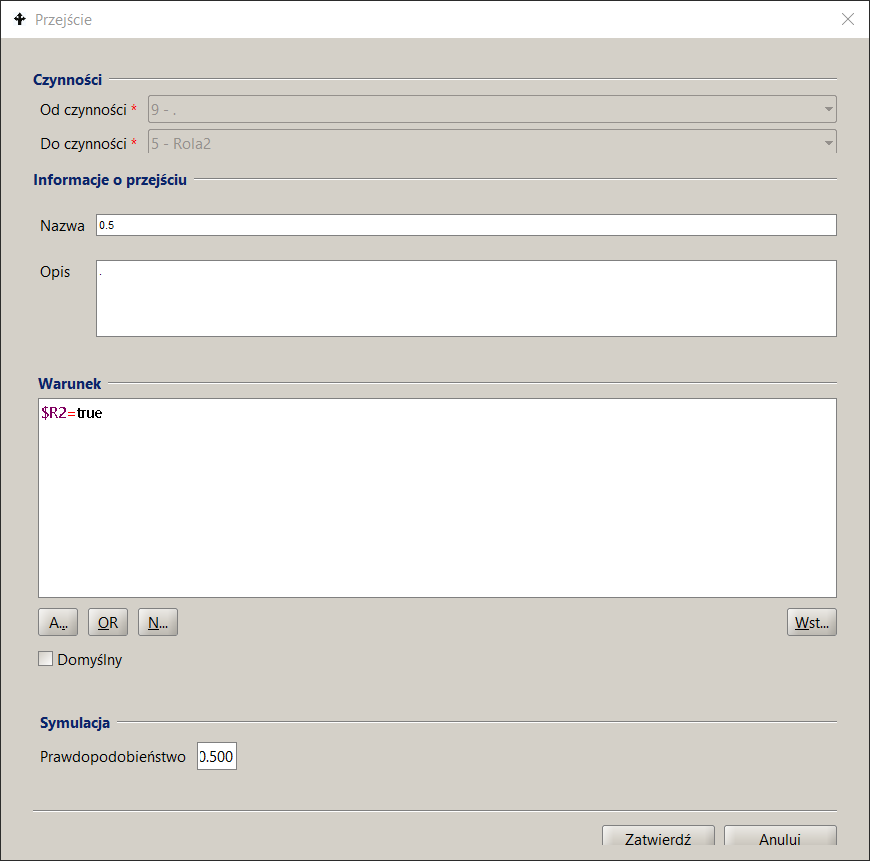
Przejście
Scenariusz
Rysunek 12. Parametryzacja modelu procesu
To drugie możemy osiągnąć przez dekompozycję czynności i zrównoleglenia przetwarzania zadań procesu albo przez automatyzację części lub całości poszczególnych zadań. W naszym przykładzie podniesiono 5-pięciokrotnie przepustowość procesu dodając 4 wykonawców do Roli2.
| ROLA 1 | ROLA 2 | Kolejka R1 (Czas) | Kolejka R2 (Czas) | Kolejka R1 (Liczba) | Kolejka R2 (Liczba) | Proces Wykonanie (Średni Czas) |
|---|---|---|---|---|---|---|
| 1 | 1 | 0,66 | 3,79 | 2,95 | 17,04 | 2,22 |
| 1 | 2 | 3,00 | 0,33 | 17,99 | 2,00 | 1,67 |
| 2 | 2 | 0,33 | 1,89 | 2,95 | 17,04 | 1,11 |
| 3 | 3 | 0,22 | 1,26 | 2,95 | 17,03 | 0,74 |
| 3 | 4 | 0,58 | 0,58 | 9,99 | 9,99 | 0,58 |
*/ Czas podany w godzinach
Tabela 10. Wyniki symulacji analitycznej 5 scenariuszy analizy MVA

Liczba instancji zadań w ramach przebiegu 20 instancji procesów
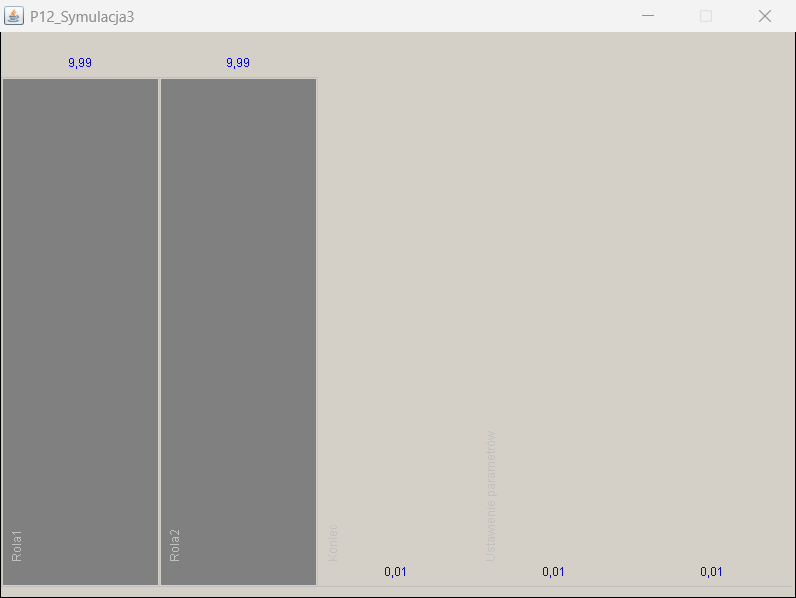
Kolejki dla zadań Rola1 i Rola2 (instancje zadań)
Czas rezydencji dla zadań Rola1 i Rola2 (czas w sekundach)
Rysunek 13. Wybrane wyniki wykonania symulacji analitycznej